Data-Driven Search and Analysis of Research Software
M.Sc. Florian Sihler
While it is great to see people focusing their life to software engineering and other related fields in computer science, it is important to keep in mind that many of those who have to code or work with code specialize in other domains.
My current research focuses on helping these people with a non-programmer background, using a combination of static and dynamic program analysis. For this, I work on a hybrid dataflow analysis algorithm for the R programming language, which is commonly used for statistical analysis. My work received the YoungRSE award at the deRSE24 and the award for the best master's degree in the field of computer science at Ulm University. If you are interested, feel free to get in touch with me or check out the flowR repository on GitHub or my portfolio website.
Furthermore, I assist in teaching:
Useful Links
View the poster here (PDF). FlowR is actively developed on GitHub at flowr-analysis/flowr.
View the poster here (PDF, LaDeWi '24). You can try the game online at: https://exia.informatik.uni-ulm.de/waddle/.

Research Projects

Topics for Theses and Projects
Dynamic and Static Program Analysis

Context
Classical code coverage techniques are widely used to give an indication of the quality of a test suite (with respect to its capability in detecting faults within the system under test).
However, they are not always effective and can be outright misleading [1, 2]. Consider a scenario in which you simply execute code within a unit test but never check whether the resulting state is as expected.
While (at least for most languages) this still ensures that the code does not raise a runtime exception, this is way too weak for most use-cases.
As one possible solution, Schuler and Zeller introduced the concept of checked coverage [3], which uses dynamic slicing to only consider the executed code that contributed to something which is checked with an assertion. Later work by Zhang and Mesbah [4] showed that such checked coverage is indeed a strong indicator of the effectiveness of a test suite.
Research Problem
In this work, we want to look at an alternative to dynamic slicing - static slicing, which does not execute the code and hence over-approximates all potential executions. In contrast to a dynamic slice on an assertion, the static slice contains all the code that could potentially affect the assertion, even if it is not executed in a particular test run. This way, we obtain additional information about the test suite and the system under test, yet we do not know whether this information is useful to gauge the effectiveness of the test suite.
Tasks
More specifically the intended steps of this work are as follows:
- Consider a well-supported language such as Java alongside an appropriate 1) static slicer, 2) dynamic slicer, and 3) coverage tool.
- Use these tools to compute the static and dynamic slices for test-suites of real-world Java projects.
- Analyze, compare, and discuss the results of the static and dynamic slices with respect to the code coverage and the effectiveness of the test suite (e.g., using mutation testing).
Related Work and Further Reading
- H. Hemmati, "How Effective Are Code Coverage Criteria?," 2015 IEEE International Conference on Software Quality, Reliability and Security, Vancouver, BC, Canada, 2015, pp. 151-156.
- Laura Inozemtseva and Reid Holmes. 2014. Coverage is not strongly correlated with test suite effectiveness. In Proceedings of the 36th International Conference on Software Engineering (ICSE 2014). Association for Computing Machinery, New York, NY, USA, 435–445.
- Schuler, D. and Zeller, A. (2013), Checked coverage: an indicator for oracle quality. Softw. Test. Verif. Reliab., 23: 531-551.
- Yucheng Zhang and Ali Mesbah. 2015. Assertions are strongly correlated with test suite effectiveness. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2015). Association for Computing Machinery, New York, NY, USA, 214–224.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
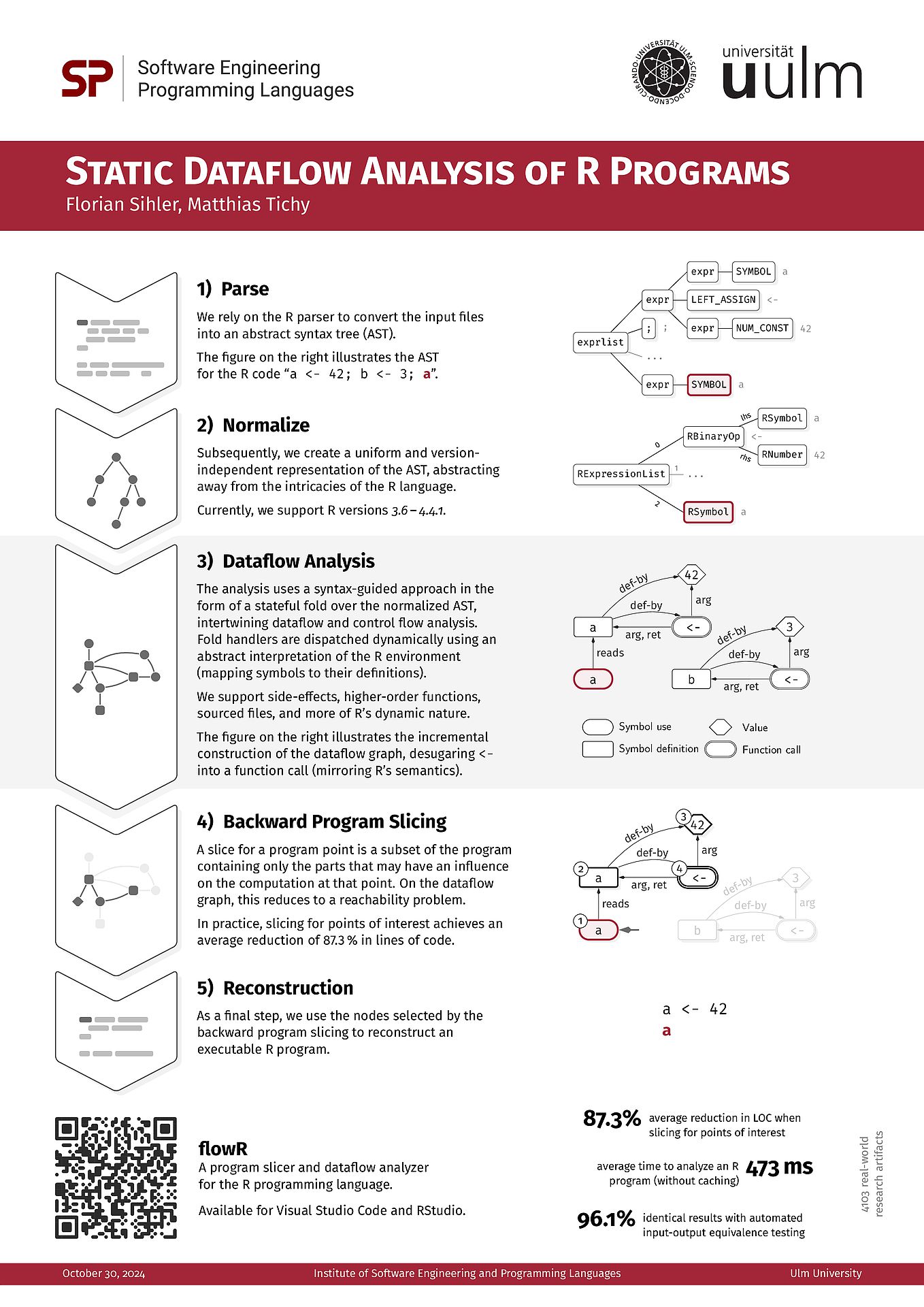
Context
Static program analysis provides us with information regarding the runtime behavior of a program without actually executing it. This is useful for various purposes, ranging from verifying the correctness of a program, over checking it for security issues to fixing issues that prevent the program from compiling or executing.
However, precise static analysis is often very expensive for larger programs making it impractical.
As a simple example, consider a case in which a method invocation may refer to a collection of implementations - based on a non-constant value that is only known at runtime. To be precise, a static analyzer has to consider every possible implementation for each method invocation, including their side-effects and transitive dependencies.
Luckily, a lot of existing research provides a plethora of possible solutions for this problem, proposing
the use of special operators [1], dynamic adjustments of the precision [2], or incremental analysis [3].
Research Problem
The goal of this thesis is to apply existing performance improvements to a static program analyzer for the R programming language and evaluating their effectiveness.
More specifically, the analyzer in question is flowR [4], which is developed here at the University of Ulm with the goal of statically handling R's powerful reflective capabilities and its deeply integrated dynamic nature.
Tasks
In the context of flowR, the main steps of the thesis are:
- Familiarize yourself with flowR's architecture and analysis algorithm
- Adapt and implement a selection of performance improvements to flowR's structure
- Evaluate the performance characteristics of the adapted versions to discuss their impact on the analysis time and precision
Related Work and Further Reading
- Vincenzo Arceri, Greta Dolcetti, and Enea Zaffanella. 2023. Speeding up Static Analysis with the Split Operator. In Proceedings of the 12th ACM SIGPLAN International Workshop on the State Of the Art in Program Analysis (SOAP 2023). Association for Computing Machinery, New York, NY, USA, 14–19.
- D. Beyer, T. A. Henzinger and G. Theoduloz, "Program Analysis with Dynamic Precision Adjustment," 2008 23rd IEEE/ACM International Conference on Automated Software Engineering, L'Aquila, Italy, 2008, pp. 29-38.
- Mudduluru, R., Ramanathan, M.K. (2014). Efficient Incremental Static Analysis Using Path Abstraction. In: Gnesi, S., Rensink, A. (eds) Fundamental Approaches to Software Engineering. FASE 2014. Lecture Notes in Computer Science, vol 8411. Springer, Berlin, Heidelberg.
- github.com/flowr-analysis/flowr
If you want to, you can have a first look at flowR for yourself [4]!
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
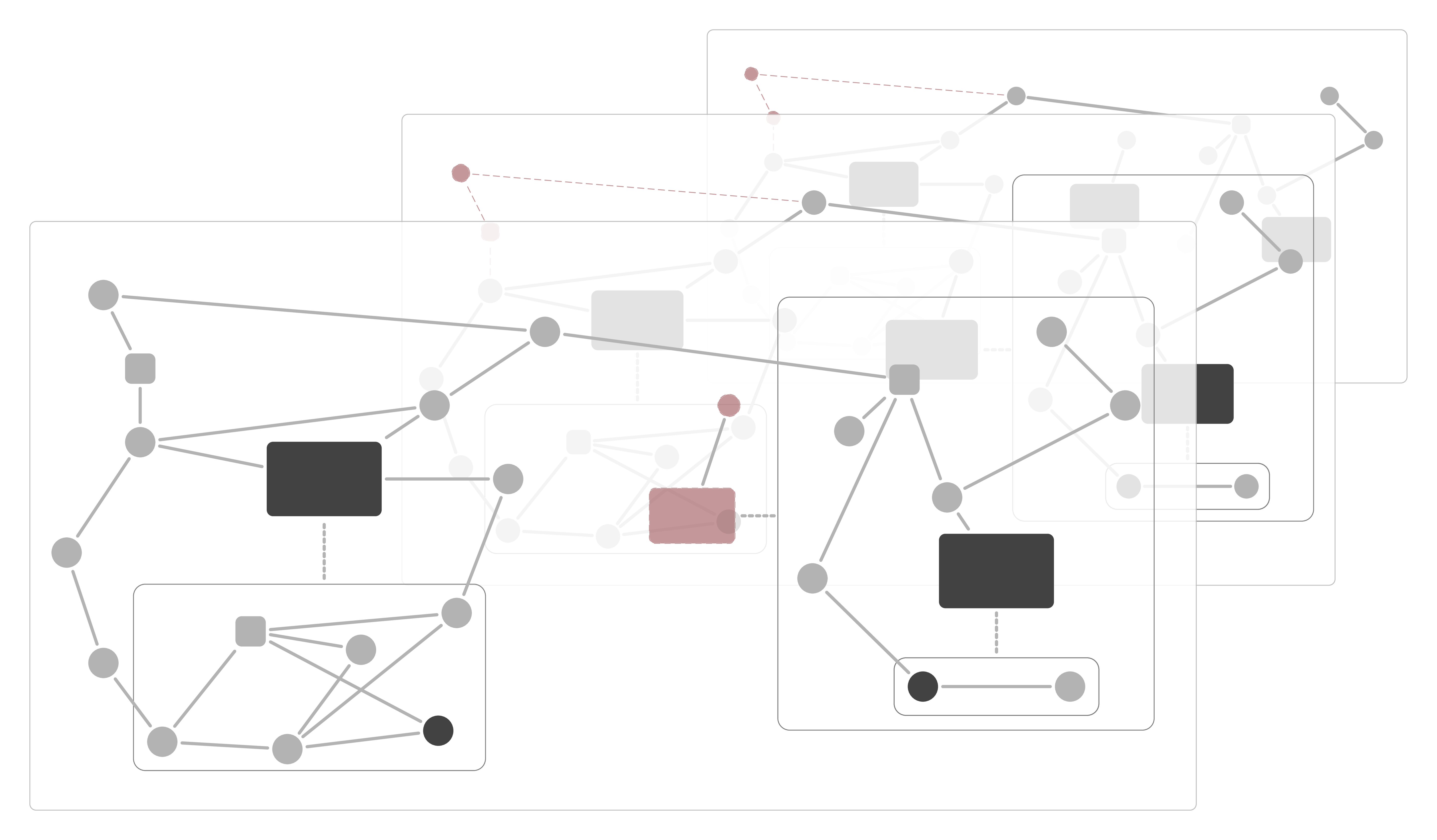
Context
Most static analyzers rely on static dataflow analysis to detect problems like possible null pointer exceptions in code [5].
However, analyzers are usually unable to handle reflective or self-modifying code (e.g., Java Agents, Java Reflection, R's meta-functions [6]). While this is fine for languages in which such constructs are rare or discouraged, they are 1) used quite often in the R programming language, 2) are in-part essential to track program semantics, 3) pose an interesting problem to solve.
Problem
As a basis, we use the static program analysis framework flowR which is designed for the R programming language [3]. flowR is currently unable to deal with reflective and code-modifying constructs like body, quote, and parse in its static dataflow graph.
While handling such constructs statically may be infeasible in the general case, we first want to focus on a set of common cases that appear frequently.
Tasks
- Develop a concept to represent code-modifications and lazy evaluation (within flowR's dataflow graph). For example, to represent a function that has the default values of its arguments or the contents of its body modified.
- Create a proof of concept implementation for this concept in flowR.
Related Work and Further Reading
- K. Cooper and L Torczon. Engineering a Compiler. (ISBN: 978-0-12-818926-9)
- U. Khedker, A. Sanyal, and B. Sathe. Data Flow Analysis: Theory and Practice. (ISBN: 978-0-8493-3251-7)
- F. Sihler. Constructing a Static Program Slicer for R Programs.
- A. Ko and B. Myers. Finding causes of program output with the Java Whyline.
- SonarQube, Sonar.
- Anckaert, B., Madou, M., De Bosschere, K. A Model for Self-Modifying Code.
If you want to, you can have a first look at flowR for yourself: https://github.com/flowr-analysis/flowr.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
![[RESERVED] B/M: Automatically Infer Code-Constraints (Sihler, Tichy)](/fileadmin/website_uni_ulm/iui.inst.170/bilder/flowR/code-contracts.png)
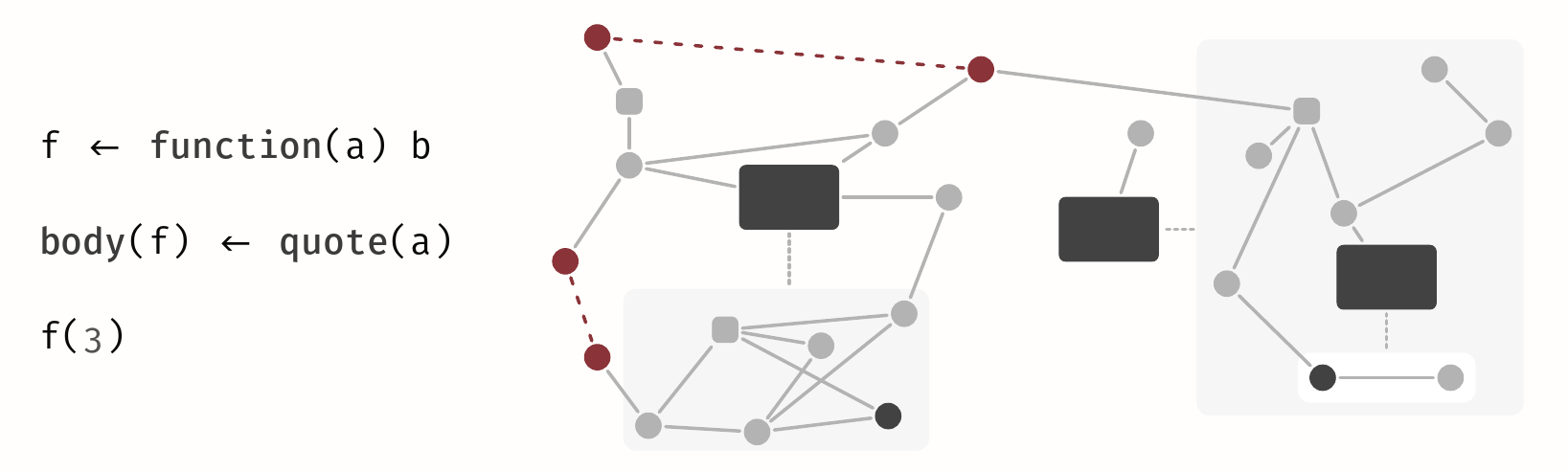
Context
Let's suppose you are a data scientist tasked with the analysis of a dataset. As an expert of the domain you have a quick look at the dataset and remember an older script by a colleague which already loads, prepares, and transforms the dataset as you want! Reusing it just leaves you with the task of visualizing the data (as is the common workflow) so you quickly write up and run the script... and luckily realize that even though the script runs and produces figures eerily close to what you would expect, something is not right. The dataset of your colleague never contained a zero so the script contains the implicit assumption of being just able to divide cells.
Within this work we want to make such implicit assumptions explicit in the code, alerting users whenever they no longer hold!
Problem
You have an R script together with the statically inferred dataflow graph that informs you about the control and data dependencies of function calls, variables, and definitions in the program.
The challenges are to
- identify points of interest at which the behavior of the program is defined,
- infer contracts that represent the potential implicit assumptions at the given position (e.g., that the value of a variable has to be non-zero, smaller than the length of another vector, ...), and
- instrument the code to automatically verify these constraints from now on.
Of course, the specific scope of these challenges as well as the focus depends on whether you want to do this as a bachelor's or master's thesis as well as your personal preference.
Tasks
- Enrich flowR [4], a dataflow analysis framework for the R programming language, with the capability to infer predefined constraints
- Create an initial collection of sensible constraints to infer (e.g., non-zero values, ...)
- Infer these constraints and instrument the program to reflect them [5]
One way to infer such constraints would be the definition of abstract domains [1] although classical optimization techniques such as constant folding and constant propagation help as well [2, 3].
Related Work and Further Reading
- P. Cousot. Principles of Abstract Interpretation. (ISBN: 978-0-26-204490-5)
- K. Cooper and L Torczon. Engineering a Compiler. (ISBN: 978-0-12-818926-9)
- U. Khedker, A. Sanyal, and B. Sathe. Data Flow Analysis: Theory and Practice. (ISBN: 978-0-8493-3251-7)
- F. Sihler. Constructing a Static Program Slicer for R Programs.
- B. Meyer, Applying "Design by Contract"
If you want to, you can have a first look at flowR for yourself: https://github.com/flowr-analysis/flowr.
Contact and More
If you are interested and/or have any questions, feel free to contact me any time.
We can discuss the topic further and try to adapt it to your personal preferences.
Florian Sihler (Institute Homepage)
[2–6 Students] [AP SE] [PSE1] [PSE2] [German version below]
Static analysis refers to the examination of programs for runtime properties without actually executing them.
It is an integral part of modern software development and aids in identifying bugs, security vulnerabilities, or improving readability.
Compilers use static analysis to, for example, avoid type errors or generate the most optimal code possible.
Development environments or language servers leverage static analysis to enable features such as refactoring or auto-completion.
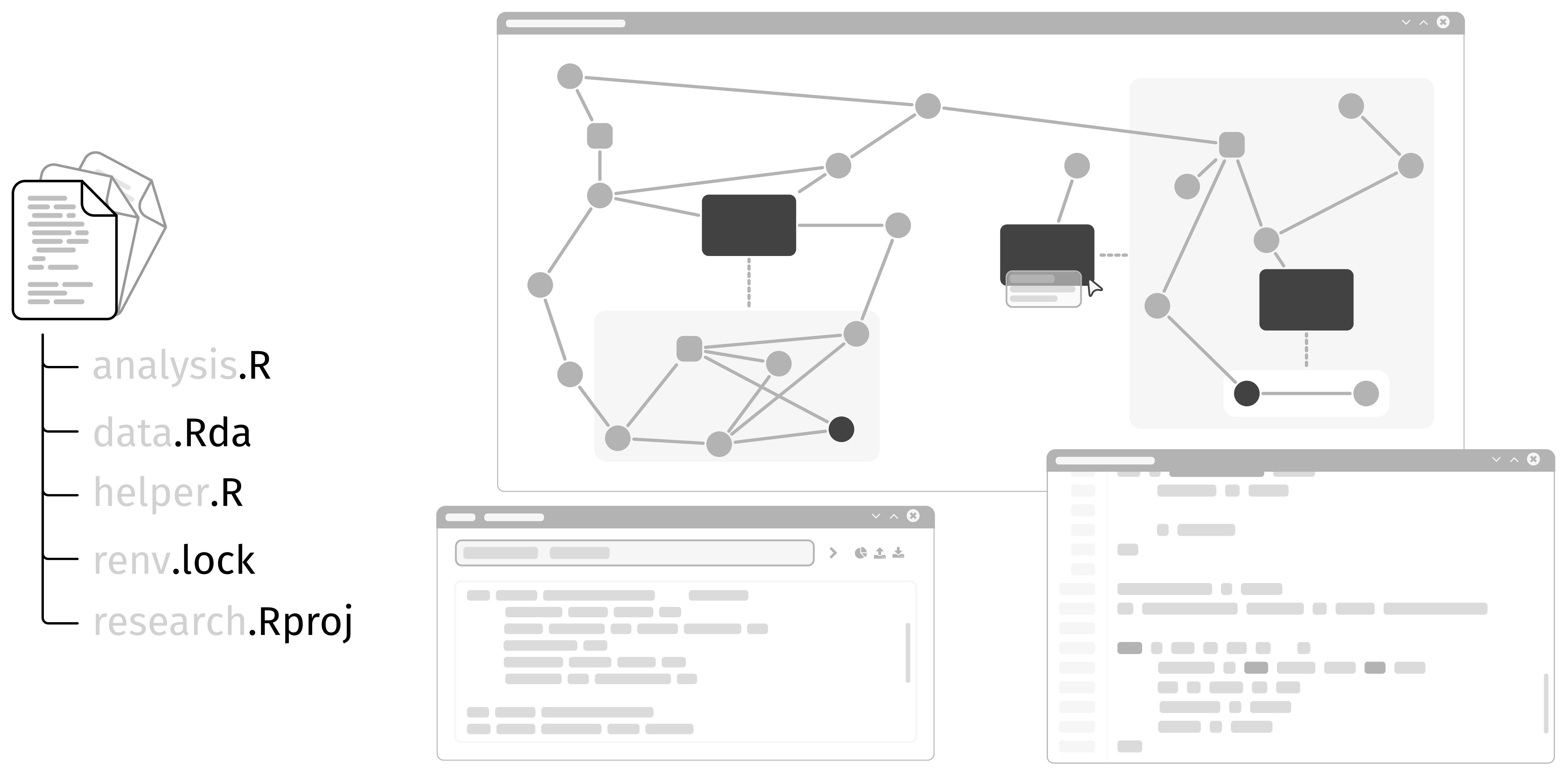
In this project, we focus on flowR, a framework for the static analysis of R, a statistical programming language widely used in data analysis and visualization.
A detailed analysis of data and control flow enables flowR to, for instance, reduce a program to only the parts relevant for generating a graphic or computing a statistical model (a technique known as Program Slicing).
About flowR
Currently, flowR can be used and tested as a Visual Studio Code extension, RStudio add-in, or directly as a Docker image.
flowR is developed primarily in TypeScript under the GPLv3 license and is hosted on GitHub.
Documentation is provided through a dedicated Wiki and directly in the code.
Goal
In this project, we aim to extend flowR with support for R projects.
While the analysis of individual and multiple scripts is already supported, this includes in particular:
- Integration with build systems like renv
- Consideration of metadata such as DESCRIPTION or NAMESPACE files
- Support for incremental updates (e.g., when individual files change)
- Resolving package relationships and dependencies
This would enable flowR to be used in larger projects and, for instance, analyze the data flow while accounting for correct package dependencies.
German Version
Statische Programm-Analyse für Projekte
Statische Analyse bezeichnet die Untersuchung von Programmen auf Laufzeiteigenschaften ohne diese tatsächlich auszuführen. Sie ist ein integraler Bestandteil moderner Softwareentwicklung und hilft beim Identifizieren von Fehlern, Sicherheitslücken oder dem Verbessern der Lesbarkeit. Compiler verwenden statische Analyse beispielsweise, um Typfehler zu vermeiden oder möglichst optimalen Code zu generieren. Entwicklungsumgebungen oder Language Server verwenden statische Analyse, um Ihre Funktionalität wie Refactorings oder Autovervollständigung zu realisieren.
In diesem Projekt widmen wir uns flowR, einem Framework für die statische Analyse von R, einer statistischen Programmiersprache die häufig in der Datenanalyse und -visualisierung eingesetzt wird. Eine ausgiebige Analyse des Daten- und Kontrollflusses ermöglicht es flowR beispielsweise ein Programm nur auf die Teile zu reduzieren, die für die Generierung einer Grafik oder die Berechnung eines statistischen Modells relevant sind (das sogenannte Program Slicing).
Über flowR
Aktuell kann flowR als Erweiterung für Visual Studio Code und RStudio, sowie direkt als Docker Image verwendet und ausprobiert werden.
flowR wird unter der GPLv3 Lizenz auf Github hauptsächlich in der Programmiersprache TypeScript entwickelt. Die Dokumentation erfolgt über ein dediziertes Wiki und direkt im Code.
Ziel
Im Anwendungsprojekt wollen wir flowR um eine Unterstützung für R Projekte zu erweitern.
Während die Analyse von einzelnen und auch mehreren Skripten bereits unterstützt wird, zählt hierzu insbesondere die:
- Integration von Build-Systemen wie renv
- Berücksichtigung von Metadaten wie DESCRIPTION oder NAMESPACE Dateien
- Unterstützung von inkrementellen Aktualisierungen (z.B. wenn sich einzelne Dateien ändern)
- Auflösung von Paketbeziehungen und Abhängigkeiten
Auf diese Weise kann flowR auch in größeren Projekten eingesetzt werden und beispielsweise den Datenfluss unter der Berücksichtigung der richtigen Paketabhängigkeiten analysieren.
Supervised and Completed Theses
Master Theses
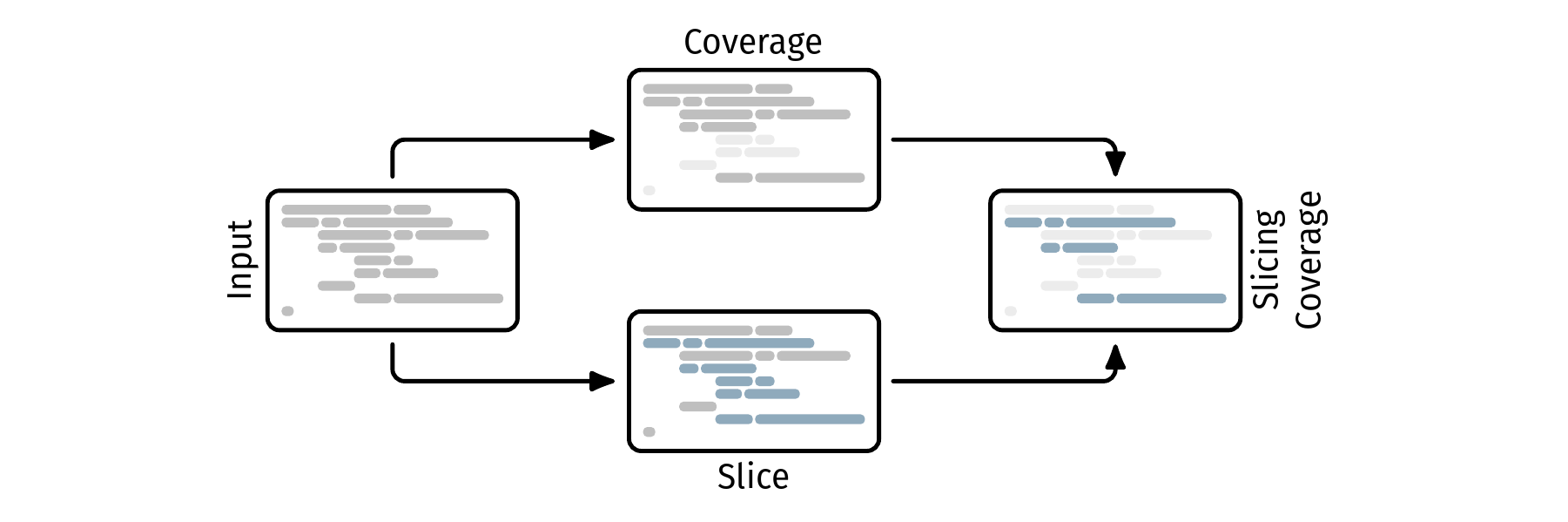
This thesis covers the development and evaluation of a novel way to determine coverage scores for the R programming language. We calculate a static backward program slice for all assertion criteria of a given test suite and use this information together with coverage information to determine the coverage of the tested code.
Testing software is a crucial part of the development process. However, determining when the software is sufficiently tested is an impossible task. Code coverage metrics aim to be a decision-making aid in this regard. But research shows, that they can be deceptive and in fact do not necessarily reflect the quality of a testsuite.
We propose slicing coverage as a novel approach that aims to enhance the accuracy of coverage scores by calculating them based on the program slice resulting from the test’s assertion criteria. We also provide a proof-of-concept implementation for the R programming language. Alongside the theoretical concept and a practical implementation, we evaluate our approach on a set of real-world R packages to demonstrate its potential benefits.
To calculate slicing coverage, we combine regular coverage information with the result of a static backward program slice for all assertions. This way, we can exclude code that was executed but had no influence on the test’s outcome, or in other words: code that was not checked by a assertion. To evaluate slicing coverage, we use two distinct experiments that i) record both slicing coverage and regular coverage scores, as well as execution time and memory usage, and ii) calculate the accuracy of slicing coverage by deliberately inserting faults into a program and measuring how many the test suite is able to detect.
Despite its potential benefits, slicing coverage’s results are inherently limited by the quality of the program slicer and coverage tool used. We also carry over some limitations of traditional coverage metrics like the inherent performance overhead. Besides those conceptual limitations, we also face practical challenges like our implementation being unable to handle implicit assumptions that are not directly encoded in the source or test code.
We find that, for the median package, the traditional and slicing coverage scores differ by 19.53 %, with the slicing coverage score being lower. The median slicing coverage score over all packages lies at 44.09 %.
With regards to memory usage, we deem our slicing coverage implementation to not be a burden on the user’s system, as, for the median package, our implementation only required 384.36 MB of memory. The maximum required memory peaked at 2.11 GB . With regards to the execution time, we come to a different conclusion. The median is, again, reasonable with 85.46 s. However, the average and maximum of 35.01 min and 11.74 h respectively show that there are outliers that require a significant amount of time.
With regards to slicing coverage’s accuracy, we find that mutants introduced in covered code are detected more often than mutants inside the program slice (p = 0.0212). This indicates that slicing coverage’s accuracy is lower than traditional coverage.
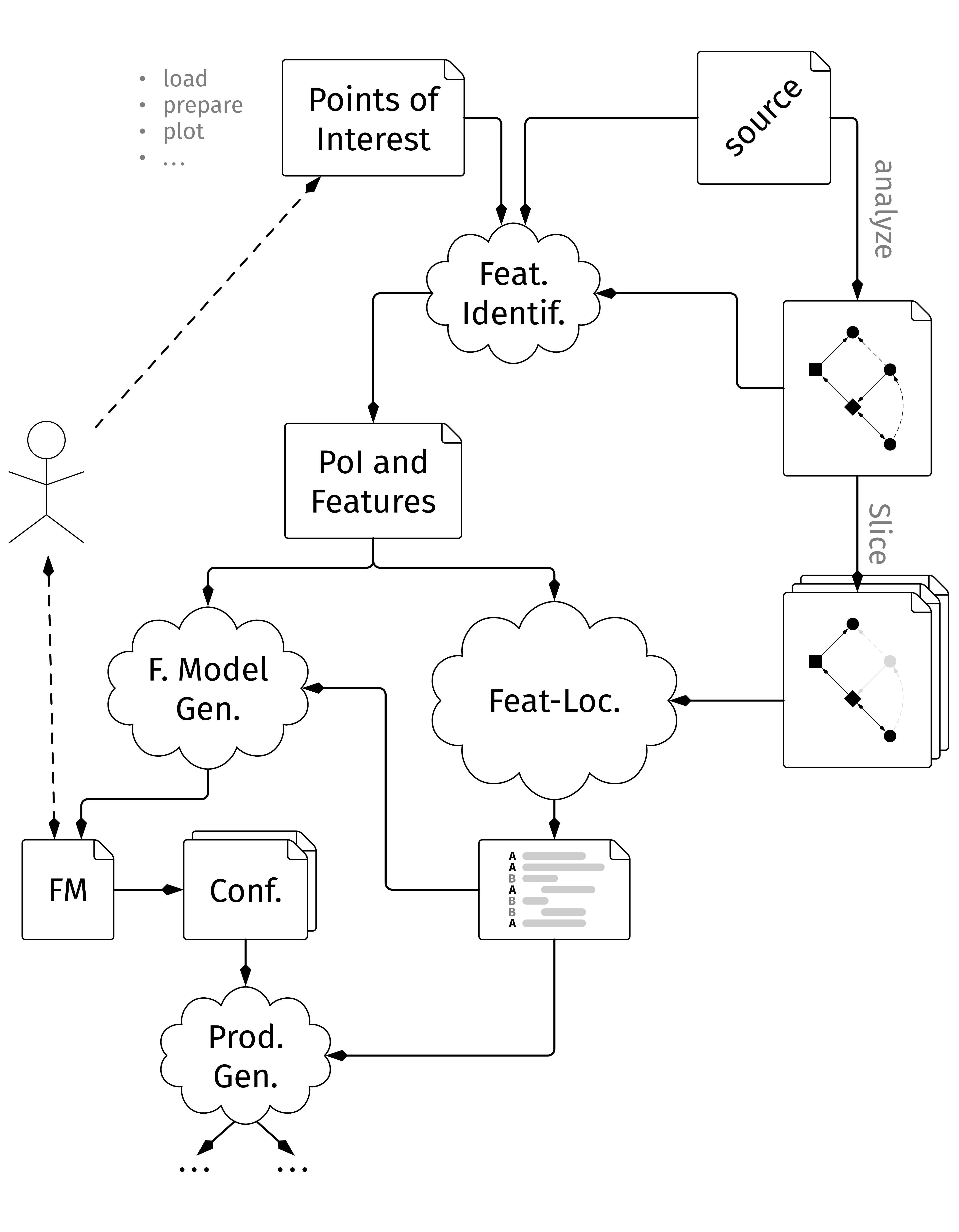
In this master thesis we describe the development and evaluating of a tool that tries to re-engineer R research scripts into a Software Product Line.
R research scripts are rarely reproducible and a different user might have a hard time comprehending a badly structured script. This creates the need for tools to support them in understanding which plot was created through which chain of actions. Going even further, some aspects of the given R research script might be reusable for a new task, but finding them is not simple, so the tool should be able to analyze the script once and then create a representation where those aspects can be marked and selected.
We propose GardenR a tool to transform a R research script by detecting Points of Interest, locating them in the source code, create dependencies for interactions with other features and annotate them in the source code through feature flags. Alongside GardenR, we collect a set of Points of Interest for the data science domain of the R programming language and use them to evaluate our tool.
First, we conceptualize the algorithms needed for the identification, localization and visualization of Points of Interest in research scripts. Then we implement those concepts, focusing on architectural decisions and specifics regarding the R programming language in particular as well as the collection of Points of Interest through labeling the exposed functions of R packages. Next, we benchmark the tool using real-world code examples.
The capabilities of our tool are currently limited due to a not fully functioning process, with the annotation of the source code creating errors during the execution. Furthermore, there exists a memory leak in the tool, which is mitigated by restarting the tool upon triggering a death flag.
We identify 12 004 functions that can be mapped to the data science process. Furthermore, our benchmarking of GardenR was able to analyze 958 out of 1 000 real-world R research scripts, detecting a median of 91 features per instance and a median increase by factor 1.29 in lines of code. Without the tool creating executable scripts, we were unable to confirm the correctness of our approach against a outputs of the source, but used tests, sanity checks and manual labeling that were compared to the results of the execution to mitigate this.
Bachelor Theses

In this bachelor thesis, we describe an algorithm for field-sensitive pointer analysis using the R programming language as an example.
While there have been numerous implementations of pointer analyses for languages such as C, C++, or JavaScript, R lacks such comprehensive support. The frequent use of composite data structures and subsetting operators in R suggests a high degree of applicability for field-sensitivity.
The described algorithm handles storing, managing, and reading pointer information. This information is used to manipulate the data flow graph in order to achieve field-sensitivity.
We first elaborate a concept that we then apply to the flowR data flow framework. Afterward, we evaluate the artifact by running a sophisticated pipeline that uses two variants of flowR, one with pointer analysis enabled and one without.
Our implementation’s capabilities are limited by the language subset that we support. In this thesis the support includes the constant definitions of atomic vectors and lists, and subsetting with constant arguments. The approach was designed to increase support for R, and we cannot apply the described algorithm to languages that treat pointers inherently differently.
Our results show that our algorithm provides a solid proof of concept, while our implementation yields a slightly greater slicing reduction for the number of normalized tokens of 82.42 ± 15.59 %, a tolerable runtime increase of 13.81 ms in the median, and a doubling in data flow graph size on average.
Publications
2025
10.
Sihler,
Florian;
Pietzschmann,
Lukas;
Straub,
Raphael;
Tichy,
Matthias;
Diera,
Andor;
Dahou,
Abdelhalim
On the Anatomy of Real-World R Code for Static Analysis (Extended Abstract)
Publisher: Gesellschaft für Informatik, Bonn
February 2025
On the Anatomy of Real-World R Code for Static Analysis (Extended Abstract)
Publisher: Gesellschaft für Informatik, Bonn
February 2025
| DOI: | 10.18420/se2025-27 |
2024
9.
Sihler,
Florian;
Tichy,
Matthias
flowR: A Static Program Slicer for R
ASE '24: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (Tool Demonstrations)
October 2024
flowR: A Static Program Slicer for R
ASE '24: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (Tool Demonstrations)
October 2024
| DOI: | 10.1145/3691620.3695359 |
8.
Sihler,
Florian
Improving the Comprehension of R Programs by Hybrid Dataflow Analysis
ASE '24: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (Doctoral Symposium)
October 2024
Improving the Comprehension of R Programs by Hybrid Dataflow Analysis
ASE '24: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (Doctoral Symposium)
October 2024
| DOI: | 10.1145/3691620.3695603 |
7.
Neumüller,
Denis;
Sihler,
Florian;
Straub,
Raphael;
Tichy,
Matthias
Exploring the Effectiveness of Abstract Syntax Tree Patterns for Algorithm Recognition
4. International Conference on Code Quality (ICCQ)
June 2024
Exploring the Effectiveness of Abstract Syntax Tree Patterns for Algorithm Recognition
4. International Conference on Code Quality (ICCQ)
June 2024
| DOI: | 10.1109/ICCQ60895.2024.10576984 |
| ISBN: | 979-8-3503-6646-4 |
6.
Sihler,
Florian;
Pietzschmann,
Lukas;
Straub,
Raphael;
Tichy,
Matthias;
Diera,
Andor;
Dahou,
Abdelhalim
On the Anatomy of Real-World R Code for Static Analysis
21st International Conference on Mining Software Repositories (MSR '24)
January 2024
On the Anatomy of Real-World R Code for Static Analysis
21st International Conference on Mining Software Repositories (MSR '24)
January 2024
| DOI: | 10.1145/3643991.3644911 |
| File: |
M.Sc. Florian Sihler

M.Sc.
Florian
Sihler
Research Assistant
Ulm University
Institute of Software Engineering and Programming Languages
Albert-Einstein-Allee 11
Institute of Software Engineering and Programming Languages
Albert-Einstein-Allee 11
89069
Ulm
Germany